As the authors of the Agile Manifesto said, “We are uncovering better ways…by doing it and helping others do it.” We’ve individually been practicing, writing about, and coaching others on user story splitting since at least 2005. Richard’s story splitting flowcharts have been downloaded hundreds of thousands of times. Working individually with clients, we found very similar patterns for what works in this space. Now as we come together to form the Humanizing Work company, we’ve consolidated and updated all our story splitting content into this new guide. This includes some of the “better ways” we’ve discovered in the last decade and a half of coaching clients to split their backlog items in a wide variety of contexts.
Rather learn from video than read this content? Check out our 80/20 Product Backlog Refinement course (only $197). It’s a deep dive into these story splitting concepts plus other related topics like Feature Mining, our method for finding the first slice of a big idea such as a new project or product.
Why Story Splitting Matters
Working from a prioritized backlog of small user stories allows a team to get value and high-quality feedback on frequent intervals. Many teams struggle to split large user stories and features into good, small stories. Instead of ending up with small vertical slices through their architecture, they get stories that look more like tasks or architectural components and fail to experience the value or feedback small stories should provide.
Fortunately, story splitting is a skill that can be learned in a relatively short time. We’ve seen teams go from struggling to fluently splitting stories with just a couple hours of practice and some simple tools. Later, we’ll look at how you can structure that practice.
What Makes a Good User Story?
Before we can talk about splitting user stories, we need to make sure we have a shared understanding of what a good story is and what sorts of things can and can’t be split into good stories.
First off, a definition: A user story is simply a description of a change in system behavior from the perspective of a user. It describes something a user wants to do with the system or wants the system to do for them that it doesn’t do today.
Notice, by the way, that this sits in the solution space rather than the problem space. It’s not a description of a person wanting to accomplish a task somewhere, as in Jobs to be Done (JTBD). It’s a description of a person wanting to accomplish something in your system. JTBD is great for customer empathy in the problem space. User stories are great for translating that customer empathy into a series of changes to a software system, while maintaining the user’s perspective throughout.
User Story Formats
You’ll often see user stories written in a particular format:
I want action or feature
so that value or goal
or sometimes
As a role
I want action or feature
This template is good in that it gets you to answer three questions in your user story:
- Who is it for?
- What do they want to do—or have the system do—that’s not possible today?
- Why do they want this?
The important thing isn’t the template, though. It’s answering the three questions.
In fact, we’ll rarely write stories using the full template. A short title is useful, whether at the top of a Post-it or in the title field of a digital tool. The title typically functions as the “what.” The “who” is often provided by a product or release vision that describes a core target customer. If the story is for the target customer, we won’t repeat ourselves. That customer acts as the default user in our story cards, and we’ll only call out exceptions. Finally, we’ll make sure we cover the why, either in the description field of the tool or in lighter print on the Post-it.
So, if we’re working on a public library website and the library patron is our default user, instead of this
I want to search for a book by its exact title
So that I find the book I want without noise in the search results
We’d write
because I know the specific book I want, and I want to avoid noise in the search results
Sometimes we come across tasks or components pretending to be a story. Even if you use magic words like, “As a developer, I want a database diagram, so that I know what the structure of the database is going to be,” it’s still a task.
INVEST in Good User Stories
Some years ago, Extreme Programming pioneer Bill Wake came up with a nice acronym for 6 key attributes of a good user story: INVEST. Let’s look at each of them.
The I stands for INDEPENDENT. This means that a good story is sufficiently self-contained that it can be prioritized by something other than technical dependency. Sometimes that means temporarily building some scaffolding so a story can be tested independently, allowing you to do it sooner to get value or reduce risk early in a project.
N is for NEGOTIABLE. A good story leaves room for collaboration around the details of what and how. Of course, as the collaboration happens and you capture more detail, the story becomes less negotiable.
V is for VALUABLE. Every story should add some increment of visible value for users. Right now, this may seem impossible. You may have a backlog full of components and infrastructure tasks pretending to be stories, which don’t add value for users. But as you develop your story splitting skills, you’ll get better at finding thin slices of functionality that deliver direct value.
(Stories don’t need to provide enough value by themselves to be worth shipping. You might need to accumulate several stories to move from valuable to marketable. We like Minimum Marketable Features, or MMFs, as a container for stories.)
E is for ESTIMABLE. A good story is defined enough that the team can estimate how big it is, usually relative to other stories in the backlog.
S is for SMALL. Our rule of thumb for small enough is, by the time a story makes it to the top of your backlog, you should be able to fit 6 to 10 into a sprint. This is about getting frequent feedback and managing risk without having too many stories to manage. This is a ratio, so it scales with things like sprint length, team size, and velocity.
Finally T is for TESTABLE. We should have some way to know we’re done with the story. It can’t just be a vague aspiration, but needs to be a concrete change in system behavior.
Of course, there’s tension between some of these attributes. As stories get smaller, for example, it becomes harder to make them independent and valuable. The more negotiable they are, the harder they are to estimate and test.
Fortunately, different attributes matter at different times. Going into sprint planning, it’s more important that stories be small, estimable, and testable. We still want some independence, negotiability, and value, but those attributes become less important. Further into the future, it’s the reverse.
User Stories Are Vertical Slices
You’ll often hear the term vertical slice in reference to good stories. This is about the shape of good stories relative to software architecture.
Vertical slice is a shorthand for “a work item that delivers a valuable change in system behavior such that you’ll probably have to touch multiple architectural layers to implement the change.” When you call the slice “done,” the system is observably more valuable to a user.
This is in contrast with a horizontal slice, which refers to a work item representing changes to one component or architectural layer that will need to be combined with changes to other components or layers to have observable value to users.
Let’s look at a really simple architecture. There’s a UI layer, some business logic, and a database. Your system may be more complicated than this, but it probably contains at least these three layers.
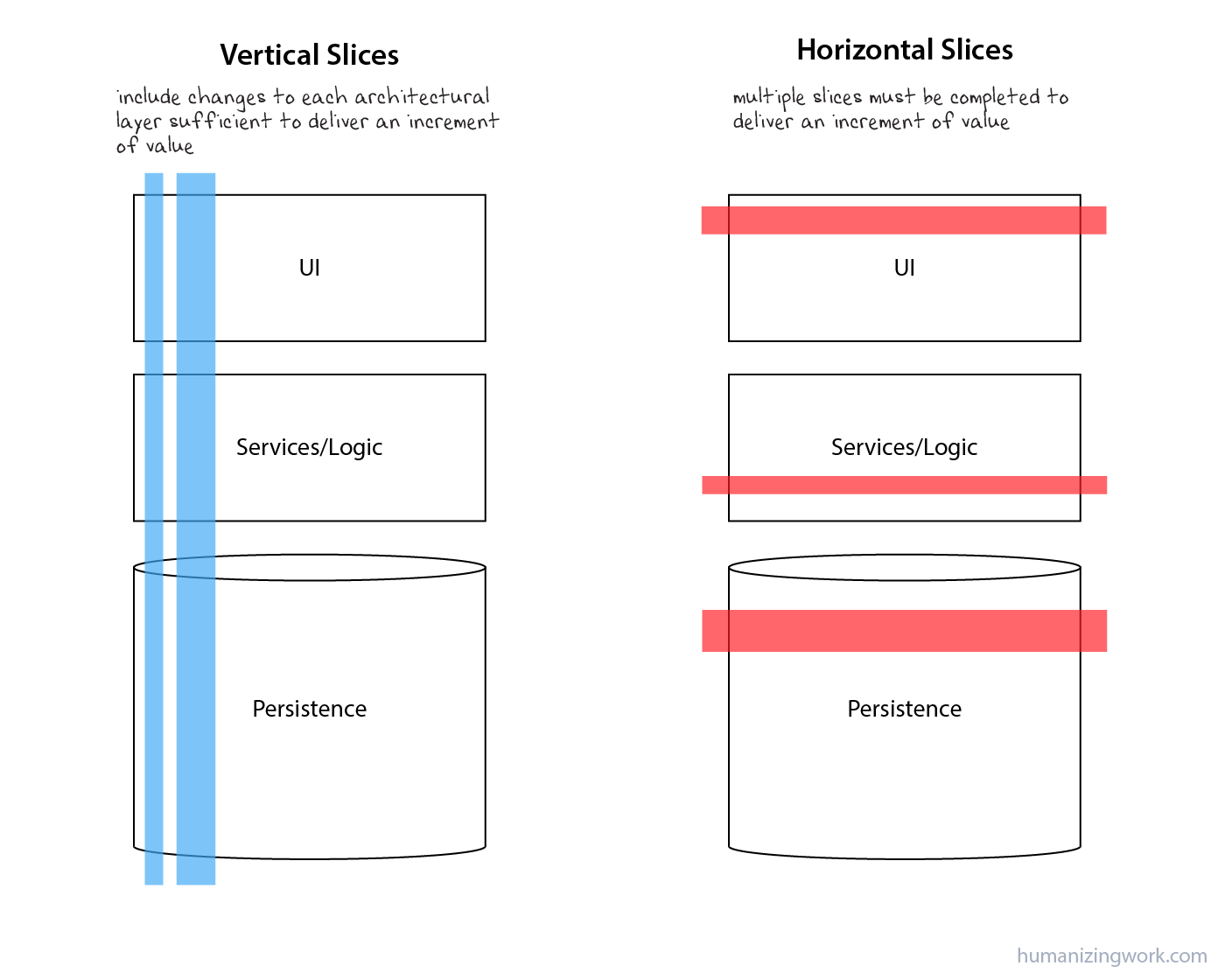
To get most of the INVEST attributes, a story is necessarily going to touch all 3 architectural layers. We probably won’t be able to deliver value without some UI changes, some logic changes, and some persistence changes. Thus, a story is a vertical slice through the system.
Sometimes those vertical slices are pretty wide. When we get into story splitting, we’ll talk about how you find thin vertical slices inside those wide ones, but for now it’s enough to know that stories should cut across architectural layers as necessary to deliver value.
Many new agile teams attempt to split stories by architectural layer: one story for the UI, another for the database, etc. This may satisfy small, but it fails at independent and valuable.
When teams work in vertical slices, they
- Make value explicit in their backlog
- Have more conversations about value
- Tend not to accidentally build low-value changes
- Get value sooner
- Get earlier, higher-quality feedback
- See constraints and inventory more easily and can respond accordingly
- Become more predictable in delivering value (because working software becomes the primary measure of progress)
We could go on, but that gives you the idea. When we sat down together and mapped out the various habits we see in successful agile teams and how they relate to each other, we found working in vertical slices enabling or at least related to virtually every other habit.
Take a look at the stories in your product backlog, some you’ve recently completed and some in the future. Evaluate each of them against the INVEST criteria. See if you can find stories that are vertical slices and stories that aren’t. Then, see if you can improve your stories.

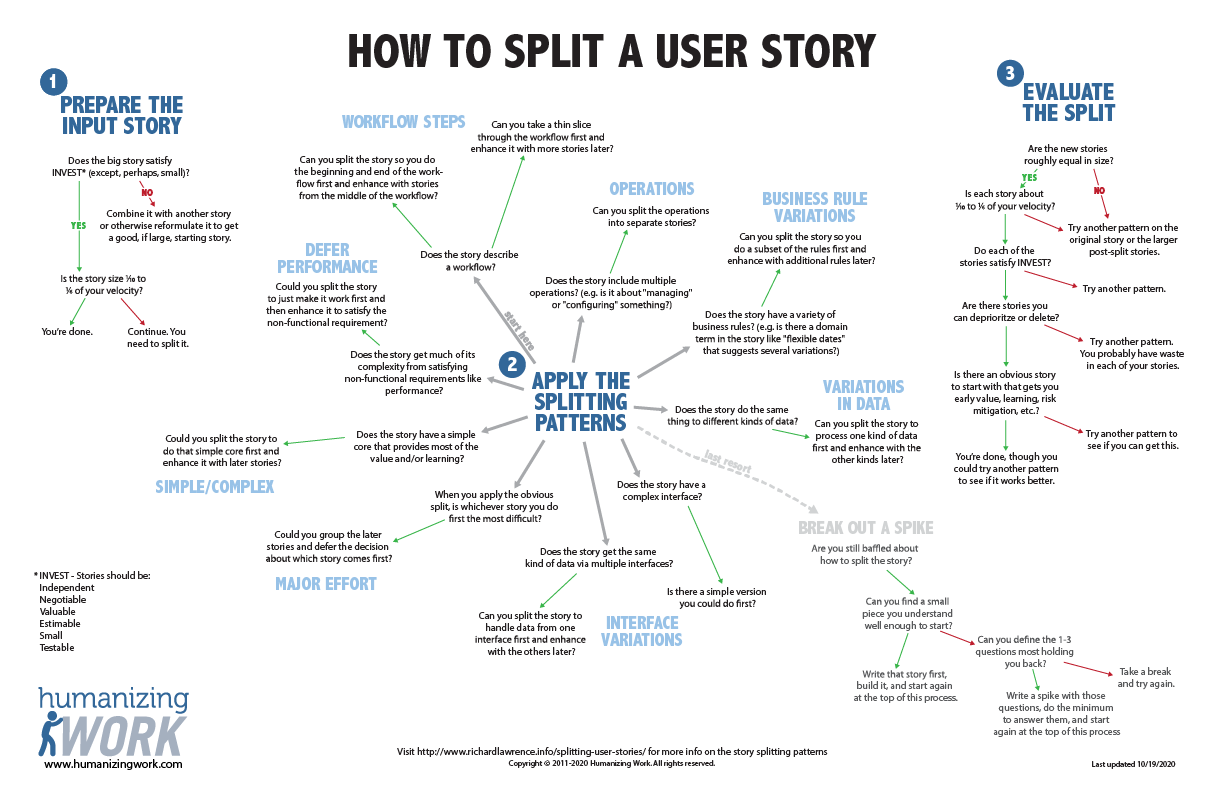
The Story Splitting Flowchart
To support the teams we coach, Richard created a story splitting flowchart that goes through the questions we’ll ask when we’re helping a team split their stories. This is your cheat sheet to an effective story splitting session. (Click the image below to download the PDF of the flowchart.)
- English – How to Split a User Story
- Chinese – 用户故事切分招数
- French – Comment Découper un Récit Utilisateur
- German – User Stories Aufteilen
- Hungarian – Hogyan daraboljuk a User Story-kat
- Japanese – ユーザーストーリーの分割方法
- Polish – Jak Dzielić Historyjki Użytkownika
- Portuguese – Como Dividir uma História de Usuário
- Romanian – Cum Împărţim o Cerinţă
- Russian – Как Разделять Истории Пользователей
- Spanish – Como Dividir una Historia de Usuario
- Turkish – BİR KULLANICI HİKAYESİ NASIL BÖLÜNEBİLİR
- Ukrainian – ЯК РОЗДІЛИТИ ІСТОРІЮ КОРИСТУВАЧА
Interested in contributing a translation into your language? Here’s how we approach new translations.
Let’s take a look at the three parts of the chart.
Step 1: Getting the input story (or feature) ready
 Start by making sure that the story (or feature) you are trying to split satisfies the INVEST criteria (other than small). Most often, Valuable is the issue. When people bring us their “unsplittable” stories, they turn out to be tasks or components masquerading as stories. If you start with something that isn’t an increment of value, there’s no way to slice it smaller and get an increment of value. In this case, the next move is to combine the non-story with the other pieces such that, together, they represent an increment of value.
Start by making sure that the story (or feature) you are trying to split satisfies the INVEST criteria (other than small). Most often, Valuable is the issue. When people bring us their “unsplittable” stories, they turn out to be tasks or components masquerading as stories. If you start with something that isn’t an increment of value, there’s no way to slice it smaller and get an increment of value. In this case, the next move is to combine the non-story with the other pieces such that, together, they represent an increment of value.
Next, is the slice too big? If it is, it’s time to split it.
Step 2: Applying the patterns
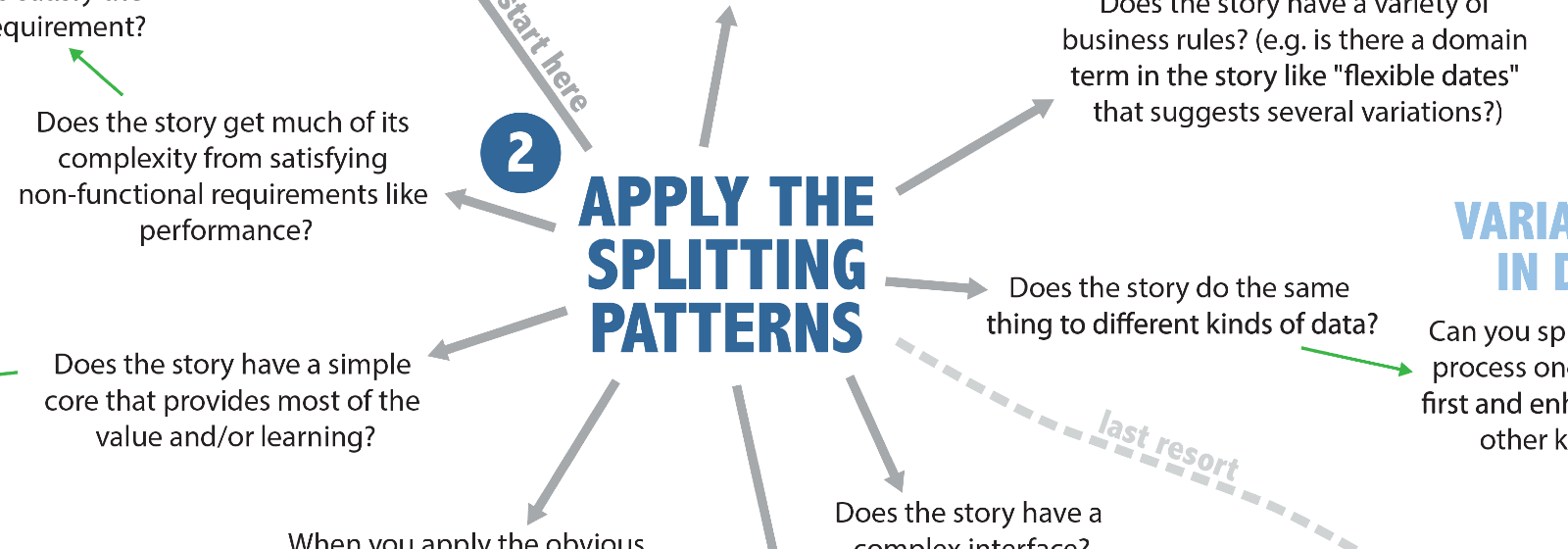
Pattern #1: Workflow Steps
Here’s a story from a content management system one of our clients was creating:
Didn’t sound too big—until we dug into the workflow to get a story published. It turned out that just to get a several sentence news story on the corporate website required both editorial and legal approval and final review on a staging site. There’s no way 6-10 stories like this would fit in an iteration.
In a workflow like this, the biggest value often comes from the beginning and end. The middle steps add incremental value, but don’t stand alone. So it can work well to build the simple end-to-end case first and then add the middle steps and special cases.
The new stories included:
…I can publish a news story with editor review.
…I can publish a news story with legal review.
…I can view a news story on a staging site.
…I can publish a news story from the staging site to production.
Sometimes, though, the whole workflow matters, so you can’t just start with the beginning and end. In those situations, look for a thin slice through the whole workflow. Maybe it supports the most common case. Maybe you hard-code or otherwise simplify the best understood parts of the workflow so you can explore the more complex parts.
Either way, the most obvious split—one step at a time from beginning to end—is the wrong way to go.
In this free lesson from my 80/20 Product Ownership online course, learn why most people split workflows wrong.
Pattern #2: Operations (e.g. CRUD)
The word “manage” in a user story is a giveaway that the story covers multiple operations. This offers a natural way to split the story. For example:
becomes
…I can edit my account settings.
…I can cancel my account.
Pattern #3: Business Rule Variations
This story has a few equally complex stories hidden within it that accomplish the same thing using different business rules:
Digging into “flexible dates” reveals several different business rules, each of which can be a good story on its own:
…as “a weekend in December.”
…as “± n days of x and y.”
Pattern #4: Variations in Data
Complexity in a story can come from handling variations in data. For example, a system we’re currently working on needs to model geographic areas served by transportation providers. We could have burned our whole project budget just handling geography; it’s potentially that complex. When we talked through the story,
with our Product Owner, we discovered that, while we didn’t need full-fledged GIS, modeling geography would still be quite complex. We stopped and asked, “What’s the ‘good enough’ way to model geography so we can build other high-value features now?” We settled on,
This worked for a while, until we collected more data and found that some providers only served certain cities or even neighborhoods. So a new story came up:
Looking over the new provider data, we also discovered that some providers will support trips originating in a single city but ending in any number of surrounding cities. This led to the story:
All three of these stories are split from the original geography story. The difference here is that we added stories just-in-time after building the simplest version.
But sometimes you know the data variations up-front. The classic example is localization:
…in English.
…in Japanese.
…in Arabic.
…etc.
Pattern #5: Data Entry Methods
Complexity sometimes is in the user interface rather than in the functionality itself. In that case, split the story to build it with the simplest possible UI and then build the more usable or fancier UI. These, of course, aren’t independent—the second story effectively is the original story if you do it first—but it still can be a useful split.
can split into
…with a fancy calendar UI.
Pattern #6: Major Effort
Sometimes a story can be split into several parts where most of the effort will go towards implementing the first one. For example, this credit card processing story,
could be split into four stories, one for each card type. But the credit card processing infrastructure will be built to support the first story; adding more card types will be relatively trivial. We could estimate the first story larger than the other three, but then we have to remember to change our estimates if the Product Owner later changes priorities. Instead, we should defer the decision about which card type gets implemented first like this:
…I can pay with all four credit card types (VISA, MC, DC, AMEX) (given one card type already implemented).
The two new stories still aren’t independent, but the dependency is much clearer than it would be with a story for each card type.
Pattern #7: Simple/Complex
When you’re in a planning meeting discussing a story, and the story seems to be getting larger and larger (“what about x?”; “have you considered y?”), stop and ask, “What’s the simplest version of this?” Capture that simple version as its own story. You’ll probably have to define some acceptance criteria on the spot to keep it simple. Then, break out all the variations and complexities into their own stories. So, for example, this story,
stays simple by splitting off variations like,
…including nearby airports.
…using flexible dates.
…etc.
This pattern is really about finding the core of the story and keeping it simple. Move every variation into its own story.
Pattern #8: Defer Performance
Sometimes, a large part of the effort is in making a feature fast—the initial implementation isn’t all that hard. But you can learn a lot from the slow implementation and it has some value to a user who wouldn’t otherwise be able to do the action in the story. In this case, break the story into “make it work” and “make it fast”:
…(slow—just get it done, show a “searching” animation).
…(in under 5 seconds).
This approach can work any non-functional requirement, not just performance. You can make it work and then make it secure. Make it work and then make it scale. Etc.
Be careful, though. It’s easy to get in a habit of calling stories done that aren’t really done, accumulating debt you’ll pay for later.
Pattern #9: Break Out a Spike
A story may be large not because it’s necessarily complex, but because the implementation is poorly understood. In this case, no amount of talking about the business part of the story will allow you to break it up. Do a time-boxed spike first to resolve uncertainty around the implementation. Then, you can do the implementation or have a better idea of how to break it up. Don’t know how to implement the following story?
Then, break it into:
Implement credit card processing.
In the “investigate” story, the acceptance criteria should be questions you need answered. Do just enough investigation to answer the questions and stop; it’s easy to get carried away doing research.
The spike split is last because it should be your last resort. You probably know enough to build something. Do that, and you’ll know more. So, make every effort to use one of the previous eight patterns before resorting to the spike pattern.
Meta-Pattern: Find the Complexity & Reduce the Variations
As we’ve coached teams through splitting stories more effectively, we’ve discovered a meta-pattern that’s common to these patterns: focus on the complexity and reduce the variations through it. Here’s how you’d use the meta-pattern directly:
- Find the core complexity. What’s the part that’s most likely to surprise you or have something emerge? It’s often the part that depends on human preferences or behavior. Sometimes, it’s the part with a new integration or external dependency.
- Identify the variations. What are there many of? Business rules, user types, interfaces, data variations, entities, etc.
- Reduce all the variations to one. Find a single, complete slice through the complex part. It might be a single scenario. Or it might be a range of scenarios through a single business rule variation.
Most of the story splitting patterns are just examples of identifying a source of variation and reducing it to one.
This approach works particularly well for the first slice of a new thing because it goes straight for the core complexity and avoids anything else that would make the work bigger.
Step 3: Evaluating the split
 You’ll often find that you can split a story using several of the patterns. Which split should you choose? We use two rules of thumb:
You’ll often find that you can split a story using several of the patterns. Which split should you choose? We use two rules of thumb:
- Choose the split that lets you deprioritize or throw away a story. The 80/20 principle says that most of the value of a user story comes from a small share of the functionality. When one split reveals low-value functionality and another doesn’t, it suggests that the latter split hides waste inside each of the small stories. Go with the split that lets you throw away the low-value stuff.
- Choose the split that gets you more equally sized small stories. The split that turns an 8 point story into four 2 point stories is more useful than the one that produces a 5 and a 3. It gives the Product Owner more freedom to prioritize parts of the functionality separately.
It may take a few tries to find the pattern that best fits the story you are trying to split—you may have to experiment to find the correct pattern.

Cynefin and Story Splitting
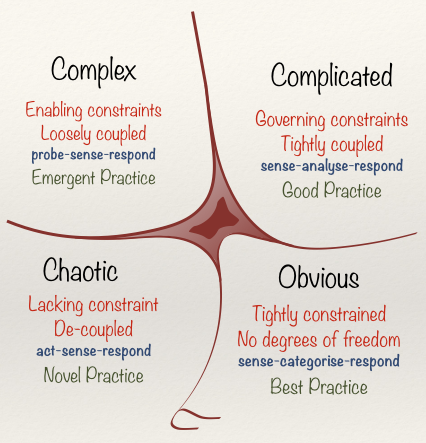 Dave Snowden’s Cynefin model is a helpful way to think about the right strategy for a problem depending on its complexity. We find Cynefin so useful, we include it in almost all our workshops, either as prerequisite content or in the workshop itself. If you’re not yet familiar with the model, check out our overview.
Dave Snowden’s Cynefin model is a helpful way to think about the right strategy for a problem depending on its complexity. We find Cynefin so useful, we include it in almost all our workshops, either as prerequisite content or in the workshop itself. If you’re not yet familiar with the model, check out our overview.
Story splitting looks different for each Cynefin domain. Here’s how:
- Obvious – Just build it. Or, if it’s too big, find all the stories, and do the most valuable ones first.
- Complicated – Find all the stories, and do the most valuable and/or most risky ones first.
- Complex – Don’t try to find all the stories. Find one or two that will provide some value and teach you something about the problem and solution, build those and use what you learn to find the rest.
- Chaotic – Put out the fire; splitting stories probably isn’t important right now.
- Disordered – Figure out which domain you’re in before splitting so you don’t take the wrong approach.
The most important nuance is in the complex domain, where starting the work will teach you about the work. In this situation, it doesn’t make sense to try to find all the small stories that add up to the original, big one. Instead, it’s more productive to find one or two you can start right away in order to learn.
Some are uncomfortable with this approach, wanting all the stories enumerated and sized to be able to project time over the backlog. But if you’re really in the complex domain, this only gives you the illusion of predictability—the actual stories are likely to change as you get into the work. Better to be transparent about the uncertainty inherent in complex work.
Getting Good at Story Splitting
As we said before, working in thin vertical slices is the key habit in Agile software development. Many people struggle to find vertical slices, but it’s a remarkably learnable skill. Teams can go from struggling to fluently identifying slices for features and big stories in their domain with only about 2.5-3 hours of practice. Of course, the quality of that practice time matters. Here’s how I recommend doing it…
Schedule two or three 1-hour practice sessions over the course of a week or two. Invite a whole team or at least a good mix of business and technical perspectives.
To prepare for the first session, look at your recent backlog from the last few months. Select a few stories or features you struggled to split but have now implemented successfully.
In Cynefin terms, these completed features are now ordered (complicated or obvious) because order emerged enough to implement them. Future work is likely to be complex and unordered. But that’s not important now. In this first practice session, your goal is to identify patterns for what makes features big in your domain. Going back to completed work is the key to the effectiveness of your practice.
In this first practice session, take one of the features or stories you selected, and walk through the questions in the story splitting flowchart together. Pretend the feature hasn’t yet been implemented but allow yourself to know what you now know about it.
If you find a good split with one of the patterns, don’t stop. Continue through the other patterns and try to find another possible split.
If one split doesn’t produce sufficiently small stories, try splitting those stories further.
After about 50 minutes, stop. For each of the story splitting patterns on the flowchart, review the examples you found in your own work.
If you didn’t find an example of a pattern in this session, take a moment to brainstorm examples from your past work. You’re trying to get a shared awareness of what these patterns look like when they show up in your domain.
If splitting completed features seemed easy by the end of this first session, you’re ready to move on to future items. If not, stick with completed items a bit longer. Find a few appropriate features before your next practice session. In that session, repeat the process above.
The hard part about this is that you actually have to treat it as practice. People are often hesitant to take time to work on developing a skill in ways other than formal training or learning by doing the job. Teams struggle sometimes to spend the time practicing splitting old features because the activity doesn’t produce a new work output—it doesn’t, for example, refine the upcoming backlog. But that aspect of the practice is the part with the most dividends in skill development. Don’t skip it.
After 2 to 3 of these sessions, you should get to a point where everyone can describe examples of each pattern in your work and quickly focus in on the appropriate pattern for future work.
Vertical Slices and Scale
Can you use vertical slices when you have 100+ people working on a single product?
When you have multiple agile teams working together on a single product, there are two primary ways you can organize: feature teams or component teams.
Feature teams are organized so that each team is sufficiently cross-functional to deliver complete slices of value (i.e. “vertical slices”) over some or all of the product. Depending on the size of the product, feature teams may specialize in parts of the product, effectively creating sub-products, or they may be able to work on whatever is most important across the whole product.
Component teams, on the other hand, are organized such that each team focuses on a particular component, architectural layer, or technology. Delivering a complete slice of value requires the coordination of the efforts of multiple teams.
Let’s consider a specific example of a fairly large business application: the QuickBooks Online accounting product. (Note: we have no idea how Intuit’s QuickBooks teams are actually organized or what the technology looks like, and it doesn’t matter for now. We just need a familiar software product to reason about.)
QuickBooks Online has a web front end. We presume it talks to a back end of some sort, probably via some service interface. There are batch processes like pulling transactions from banks, processing payroll, paying bills, and doing various things with taxes.
With a component team structure, you’d have web teams, for example, who could make changes to the web user interface but who would likely depend on back end teams making corresponding changes to their part of the system. Coordination across teams would focus on making sure their work aligns to provide value.
With a feature team structure, you might have a team or small group of teams responsible for, say, the general ledger part of the user experience, another responsible for the reporting, and a third responsible for payroll. Each of these teams would have the front end and back end skills on their team. In this case, coordination across teams would focus on making sure design and architecture align throughout the product.
The same product, but with teams organized two different ways for two different sets of outcomes and tradeoffs.
So, the answer to the question of whether vertical slices are relevant at scale depends on how you’re organized. Component teams are an explicit decision not to work in vertical slices. Component teams could coordinate their work around larger vertical slices like MMFs, but at the work item level, they lack the cross-functionality required to complete a vertical slice within a team. In other words, structuring into component teams intentionally gives up the list of outcomes above in order to optimize for something else (usually easier architectural alignment or higher utilization of specialized technical skills).
Feature teams, of course, make the opposite tradeoffs. They’re designed to deliver vertical slices and get all the benefits we listed above (with the cost of needing to explicitly coordinate for architectural alignment).
Feature teams vs. component teams is about the primary organizing approach. Naturally, there are nuances and hybrids and change over time. We’ve written about this before, particularly in the context of transforming an organization with a big legacy product.
Should you ever have 100+ people working on a single product?
Now, there’s a more important question on our mind, which is this: Regardless of whether or not we can use vertical slices on a large product or project—and as we’ve shown, we can if we organize in feature teams—is it actually effective to have that many people on one effort?
Each person or team added to a single product (or project) brings some productivity and some coordination overhead. A project of one is nearly pure productivity. Add a second person, and you don’t get twice the productivity—you get some incremental productivity, but some portion of both people’s time is now devoted to coordination. Add a third person, and you again get an increment of productivity plus increased coordination overhead. This coordination load increases exponentially with the number of connections between people.
We mitigate this to some extent by organizing into teams, so that each person only needs to coordinate on the details of their work with a small number of people, and by attempting to divide the work between teams to minimize dependencies. But the more complex the work, the less predictable the dependencies, and the more likely coordination between teams will need to happen.
Thus, at some point, adding another person or team not only fails to add an increment of productivity but also imposes a coordination cost across the whole system, such that the overall productivity goes down.
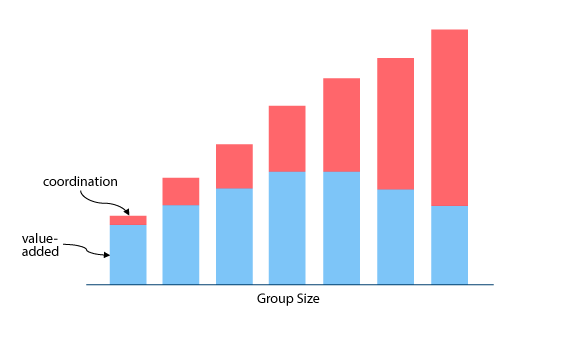
Exactly where this point falls is highly context-dependent. But the shape of the curves ought to at least make us suspicious of large projects and hesitant to add people or teams.
This is especially the case for complex work, where we’re likely to learn about the problem and solution as we do the work. And in software development, complexity seems to be highly correlated to value. If it’s valuable, it probably doesn’t exist yet. And if it’s new, we’re highly likely to learn something as we do the work.
The Bottom Line on Vertical Slices at Scale
Yes, you can work in vertical slices at each level of detail and on large and small efforts, and there is great value in doing so. But at the larger scale, you need to organize in a particular way: in feature teams, or in some hybrid that emphasizes the delivery of features. And while you’re at it, it’s worth considering whether being that large actually serves your needs.
Next Steps
We’d love to help you get better at story splitting and other key Product Owner skills.
80/20 Product Backlog Refinement Online Training (only $197). This self-paced course is a deep dive into these story splitting concepts plus other related topics like Feature Mining, our method for finding the first slice of a big idea such as a new project or product.
I’ve used the How to Split a User Story Flowchart poster with my teams for quite some time—but with varying results. I love how this course walks me through a concrete way of practicing to produce the results we are looking for. (Cristy, ScrumMaster)
Live Product Owner workshops. Join us for one of our public CSPO and A-CSPO workshops. Or contact us about private training and coaching for your organization.
Live Story Splitting for Coaches Workshop. Helping others learn how work in small vertical slices of values is a whole different thing from learning how to do it yourself. On May 21, we’ll pull back the curtain on how to coach story splitting. Register here.
Join us for a product owner workshop or our 80/20 Product Ownership online course, or contact us about private training and coaching for your organization.